Что такое кодирование и декодирование информации? Алфавит кодирования. Что такое кодирование и декодирование Примеры кодирования и декодирования информации
Информация и ее кодирование
Различные подходы к определению понятия «информация». Виды информационных процессов. Информационный аспект в деятельности человека
Информация (лат. informatio — разъяснение, изложение, набор сведений) — базовое понятие в информатике, которому нельзя дать строгого определения, а можно только пояснить:
- информация — это новые факты, новые знания;
- информация — это сведения об объектах и явлениях окружающей среды, которые повышают уровень осведомленности человека;
- информация — это сведения об объектах и явлениях окружающей среды, которые уменьшают степень неопределенности знаний об этих объектах или явлениях при принятии определенных решений.
Понятие «информация» является общенаучным, т. е. используется в различных науках: физике, биологии, кибернетике, информатике и др. При этом в каждой науке данное понятие связано с различными системами понятий. Так, в физике информация рассматривается как антиэнтропия (мера упорядоченности и сложности системы). В биологии понятие «информация» связывается с целесообразным поведением живых организмов, а также с исследованиями механизмов наследственности. В кибернетике понятие «информация» связано с процессами управления в сложных системах.
Основными социально значимыми свойствами информации являются:
- полезность;
- доступность (понятность);
- актуальность;
- полнота;
- достоверность;
- адекватность.
В человеческом обществе непрерывно протекают информационные процессы: люди воспринимают информацию из окружающего мира с помощью органов чувств, осмысливают ее и принимают определенные решения, которые, воплощаясь в реальные действия, воздействуют на окружающий мир.
Информационный процесс — это процесс сбора (приема), передачи (обмена), хранения, обработки (преобразования) информации.
Сбор информации — это процесс поиска и отбора необходимых сообщений из разных источников (работа со специальной литературой, справочниками; проведение экспериментов; наблюдения; опрос, анкетирование; поиск в информационно-справочных сетях и системах и т. д.).
Передача информации — это процесс перемещения сообщений от источника к приемнику по каналу передачи. Информация передается в форме сигналов — звуковых, световых, ультразвуковых, электрических, текстовых, графических и др. Каналами передачи могут быть воздушное пространство, электрические и оптоволоконные кабели, отдельные люди, нервные клетки человека и т. д.
Хранение информации — это процесс фиксирования сообщений на материальном носителе. Сейчас для хранения информации используются бумага, деревянные, тканевые, металлические и другие поверхности, кино- и фотопленки, магнитные ленты, магнитные и лазерные диски, флэш-карты и др.
Обработка информации — это процесс получения новых сообщений из имеющихся. Обработка информации является одним из основных способов увеличения ее количества. В результате обработки из сообщения одного вида можно получить сообщения других видов.
Защита информации — это процесс создания условий, которые не допускают случайной потери, повреждения, изменения информации или несанкционированного доступа к ней. Способами защиты информации являются создание ее резервных копий, хранение в защищенном помещении, предоставление пользователям соответствующих прав доступа к информации, шифрование сообщений и др.
Язык как способ представления и передачи информации
В зависимости от способа восприятия знаки делятся на:
- зрительные (буквы и цифры, математические знаки, музыкальные ноты, дорожные знаки и др.);
- слуховые (устная речь, звонки, сирены, гудки и др.);
- осязательные (азбука Брайля для слепых, жесты-касания и др.);
- обонятельные;
- вкусовые.
Для долговременного хранения знаки записывают на носители информации.
Для передачи информации используются знаки в виде сигналов (световые сигналы светофора, звуковой сигнал школьного звонка и т. д.).
По способу связи между формой и значением знаки делятся на:
- иконические — их форма похожа на отображаемый объект (например, значок папки «Мой компьютер» на «Рабочем столе» компьютера);
- символы — связь между их формой и значением устанавливается по общепринятому соглашению (например, буквы, математические символы ∫, ≤, ⊆, ∞; символы химических элементов).
Для представления информации используются знаковые системы, которые называются языками . Основу любого языка составляет алфавит — набор символов, из которых формируется сообщение, и набор правил выполнения операций над символами.
Языки делятся на:
- естественные (разговорные) — русский, английский, немецкий и др.;
- формальные — встречающиеся в специальных областях человеческой деятельности (например, язык алгебры, языки программирования, электрических схем и др.)
Системы счисления также можно рассматривать как формальные языки. Так, десятичная система счисления — это язык, алфавит которого состоит из десяти цифр 0..9, двоичная система счисления — язык, алфавит которого состоит из двух цифр — 0 и 1.
Методы измерения количества информации: вероятностный и алфавитный
Единицей измерения количества информации является бит . 1 бит — это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Связь между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Например, пусть шарик находится в одной из четырех коробок. Таким образом, имеется четыре равновероятных события (N = 4). Тогда по формуле Хартли 4 = 2 I . Отсюда I = 2. То есть сообщение о том, в какой именно коробке находится шарик, содержит 2 бита информации.
Алфавитный подход
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка (алфавит) можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет каждый символ:
Например, в русском языке 32 буквы (буква ё обычно не используется), т. е. количество событий будет равно 32. Тогда информационный объем одного символа будет равен:
I = log 2 32 = 5 битов.
Если N не является целой степенью 2, то число log 2 N не является целым числом, и для I надо выполнять округление в большую сторону. При решении задач в таком случае I можно найти как log 2 N", где N′ — ближайшая к N степень двойки — такая, что N′ > N.
Например, в английском языке 26 букв. Информационный объем одного символа можно найти так:
N = 26; N" = 32; I = log 2 N" = log 2 (2 5) = 5 битов.
Если количество символов алфавита равно N, а количество символов в записи сообщения равно М, то информационный объем данного сообщения вычисляется по формуле:
I = M · log 2 N.
Примеры решения задач
Пример 1. Световое табло состоит из лампочек, каждая из которых может находиться в одном из двух состояний («включено» или «выключено»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 50 различных сигналов?
Решение. С помощью n лампочек, каждая из которых может находиться в одном из двух состояний, можно закодировать 2 n сигналов. 2 5 < 50 < 2 6 , поэтому пяти лампочек недостаточно, а шести хватит.
Ответ: 6.
Пример 2. Метеорологическая станция ведет наблюдения за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100, которое записывается при помощи минимально возможного количества битов. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
Решение. В данном случае алфавитом является множество целых чисел от 0 до 100. Всего таких значений 101. Поэтому информационный объем результатов одного измерения I = log 2 101. Это значение не будет целочисленным. Заменим число 101 ближайшей к нему степенью двойки, большей 101. Это число 128 = 27. Принимаем для одного измерения I = log 2 128 = 7 битов. Для 80 измерений общий информационный объем равен:
80 · 7 = 560 битов = 70 байтов.
Ответ: 70 байтов.
Вероятностный подход
Вероятностный подход к измерению количества информации применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
$I=-∑↙{i=1}↖{N}p_ilog_2p_i$,
где $I$ — количество информации;
$N$ — количество возможных событий;
$p_i$ — вероятность $i$-го события.
Например, пусть при бросании несимметричной четырехгранной пирамидки вероятности отдельных событий будут равны:
$p_1={1}/{2}, p_2={1}/{4}, p_3={1}/{8}, p_4={1}/{8}$.
Тогда количество информации, которое будет получено после реализации одного из них, можно вычислить по формуле Шеннона:
$I=-({1}/{2}·log_2{1}/{2}+{1}/{4}·log_2{1}/{4}+{1}/{8}·log_2{1}/{8}+{1}/{8}·log_2{1}/{8})={14}/{8}$ битов $= 1.75 $бита.
Единицы измерения количества информации
Наименьшей единицей информации является бит (англ. binary digit (bit) — двоичная единица информации).
Бит — это количество информации, необходимое для однозначного определения одного из двух равновероятных событий. Например, один бит информации получает человек, когда он узнает, опаздывает с прибытием нужный ему поезд или нет, был ночью мороз или нет, присутствует на лекции студент Иванов или нет и т. д.
В информатике принято рассматривать последовательности длиной 8 битов. Такая последовательность называется байтом.
Производные единицы измерения количества информации:
1 байт = 8 битов
1 килобайт (Кб) = 1024 байта = 2 10 байтов
1 мегабайт (Мб) = 1024 килобайта = 2 20 байтов
1 гигабайт (Гб) = 1024 мегабайта = 2 30 байтов
1 терабайт (Тб) = 1024 гигабайта = 2 40 байтов
Процесс передачи информации. Виды и свойства источников и приемников информации. Сигнал, кодирование и декодирование, причины искажения информации при передаче
Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними.
В качестве источника информации может выступать живое существо или техническое устройство. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал.
Сигнал — это материально-энергетическая форма представления информации. Другими словами, сигнал — это переносчик информации, один или несколько параметров которого, изменяясь, отображают сообщение. Сигналы могут быть аналоговыми (непрерывными) или дискретными (импульсными).
Сигнал посылается по каналу связи. В результате в приемнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Примеры решения задач
Пример 1. Для кодирования букв А, З, Р, О используются двухразрядные двоичные числа 00, 01, 10, 11 соответственно. Этим способом закодировали слово РОЗА и результат записали шестнадцатеричным кодом. Указать полученное число.
Решение. Запишем последовательность кодов для каждого символа слова РОЗА: 10 11 01 00. Если рассматривать полученную последовательность как двоичное число, то в шестнадцатеричном коде оно будет равно: 1011 0100 2 = В4 16 .
Ответ: В4 16 .
Скорость передачи информации и пропускная способность канала связи
Прием/передача информации может происходить с разной скоростью. Количество информации, передаваемое за единицу времени, есть скорость передачи информации , или скорость информационного потока.
Скорость выражается в битах в секунду (бит/с) и кратных им Кбит/с и Мбит/с, а также в байтах в секунду (байт/с) и кратных им Кбайт/с и Мбайт/с.
Максимальная скорость передачи информации по каналу связи называется пропускной способностью канала.
Примеры решения задач
Пример 1. Скорость передачи данных через ADSL-соединение равна 256000 бит/с. Передача файла через данное соединение заняла 3 мин. Определите размер файла в килобайтах.
Решение. Размер файла можно вычислить, если умножить скорость передачи информации на время передачи. Выразим время в секундах: 3 мин = 3 ⋅ 60 = 180 с. Выразим скорость в килобайтах в секунду: 256000 бит/с = 256000: 8: 1024 Кбайт/с. При вычислении размера файла для упрощения расчетов выделим степени двойки:
Размер файла = (256000: 8: 1024) ⋅ (3 ⋅ 60) = (2 8 ⋅ 10 3: 2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = (2 8 ⋅ 125 ⋅ 2 3: 2 3: 2 10) ⋅ (3 ⋅ 15 ⋅ 2 2) = 125 ⋅ 45 = 5625 Кбайт.
Ответ: 5625 Кбайт.
Представление числовой информации. Сложение и умножение в разных системах счисления
Представление числовой информации с помощью систем счисления
Для представления информации в компьютере используется двоичный код, алфавит которого состоит из двух цифр — 0 и 1. Каждая цифра машинного двоичного кода несет количество информации, равное одному биту.
Система счисления — это система записи чисел с помощью определенного набора цифр.
Система счисления называется позиционной , если одна и та же цифра имеет различное значение, которое определяется ее местом в числе.
Позиционной является десятичная система счисления. Например, в числе 999 цифра «9» в зависимости от позиции означает 9, 90, 900.
Римская система счисления является непозиционной . Например, значение цифры Х в числе ХХІ остается неизменным при вариации ее положения в числе.
Позиция цифры в числе называется разрядом . Разряд числа возрастает справа налево, от младших разрядов к старшим.
Количество различных цифр, употребляемых в позиционной системе счисления, называется ее основанием .
Развернутая форма числа — это запись, которая представляет собой сумму произведений цифр числа на значение позиций.
Например: 8527 = 8 ⋅ 10 3 + 5 ⋅ 10 2 + 2 ⋅ 10 1 + 7 ⋅ 10 0 .
Развернутая форма записи чисел произвольной системы счисления имеет вид
$∑↙{i=n-1}↖{-m}a_iq^i$,
где $X$ — число;
$a$ — цифры численной записи, соответствующие разрядам;
$i$ — индекс;
$m$ — количество разрядов числа дробной части;
$n$ — количество разрядов числа целой части;
$q$ — основание системы счисления.
Например, запишем развернутую форму десятичного числа $327.46$:
$n=3, m=2, q=10.$
$X=∑↙{i=2}↖{-2}a_iq^i=a_2·10^2+a_1·10^1+a_0·10^0+a_{-1}·10^{-1}+a_{-2}·10^{-2}=3·10^2+2·10^1+7·10^0+4·10^{-1}+6·10^{-2}$
Если основание используемой системы счисления больше десяти, то для цифр вводят условное обозначение со скобкой вверху или буквенное обозначение: В — двоичная система, О — восмеричная, Н — шестнадцатиричная.
Например, если в двенадцатеричной системе счисления 10 = А, а 11 = В, то число 7А,5В 12 можно расписать так:
7А,5В 12 = В ⋅ 12 -2 + 5 ⋅ 2 -1 + А ⋅ 12 0 + 7 ⋅ 12 1 .
В шестнадцатеричной системе счисления 16 цифр, обозначаемых 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, что соответствует следующим числам десятеричной системы счисления: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15. Примеры чисел: 17D,ECH; F12AH.
Перевод чисел в позиционных системах счисления
Перевод чисел из произвольной системы счисления в десятичную
Для перевода числа из любой позиционной системы счисления в десятичную необходимо использовать развернутую форму числа, заменяя, если это необходимо, буквенные обозначения соответствующими цифрами. Например:
1101 2 = 1 ⋅ 2 3 + 1 ⋅ 2 2 + 0 ⋅ 2 1 + 1 ⋅ 2 0 = 13 10 ;
17D,ECH = 12 ⋅ 16 -2 + 14 ⋅ 16 -1 + 13 ⋅ 160 + 7 ⋅ 16 1 + 1 ⋅ 16 2 = 381,921875.
Перевод чисел из десятичной системы счисления в заданную
Для преобразования целого числа десятичной системы счисления в число любой другой системы счисления последовательно выполняют деление нацело на основание системы счисления, пока не получат нуль. Числа, которые возникают как остаток от деления на основание системы, представляют собой последовательную запись разрядов числа в выбранной системе счисления от младшего разряда к старшему. Поэтому для записи самого числа остатки от деления записывают в обратном порядке.
Например, переведем десятичное число 475 в двоичную систему счисления. Для этого будем последовательно выполнять деление нацело на основание новой системы счисления, т. е. на 2:
Читая остатки от деления снизу вверх, получим 111011011.
Проверка:
1 ⋅ 2 8 + 1 ⋅ 2 7 + 1 ⋅ 2 6 + 0 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 1 + 2 + 8 + 16 + 64 + 128 + 256 = 475 10 .
Для преобразования десятичных дробей в число любой системы счисления последовательно выполняют умножение на основание системы счисления, пока дробная часть произведения не будет равна нулю. Полученные целые части являются разрядами числа в новой системе, и их необходимо представлять цифрами этой новой системы счисления. Целые части в дальнейшем отбрасываются.
Например, переведем десятичную дробь 0,375 10 в двоичную систему счисления:

Полученный результат — 0,011 2 .
Не каждое число может быть точно выражено в новой системе счисления, поэтому иногда вычисляют только требуемое количество разрядов дробной части.
Перевод чисел из двоичной системы счисления в восьмеричную и шестнадцатеричную и обратно
Для записи восьмеричных чисел используются восемь цифр, т. е. в каждом разряде числа возможны 8 вариантов записи. Каждый разряд восьмеричного числа содержит 3 бита информации (8 = 2 І ; І = 3).
Таким образом, чтобы из восьмеричной системы счисления перевести число в двоичный код, необходимо каждую цифру этого числа представить триадой двоичных символов. Лишние нули в старших разрядах отбрасываются.
Например:
1234,777 8 = 001 010 011 100,111 111 111 2 = 1 010 011 100,111 111 111 2 ;
1234567 8 = 001 010 011 100 101 110 111 2 = 1 010 011 100 101 110 111 2 .
При переводе двоичного числа в восьмеричную систему счисления нужно каждую триаду двоичных цифр заменить восьмеричной цифрой. При этом, если необходимо, число выравнивается путем дописывания нулей перед целой частью или после дробной.
Например:
1100111 2 = 001 100 111 2 = 147 8 ;
11,1001 2 = 011,100 100 2 = 3,44 8 ;
110,0111 2 = 110,011 100 2 = 6,34 8 .
Для записи шестнадцатеричных чисел используются шестнадцать цифр, т. е. для каждого разряда числа возможны 16 вариантов записи. Каждый разряд шестнадцатеричного числа содержит 4 бита информации (16 = 2 І ; І = 4).
Таким образом, для перевода двоичного числа в шестнадцатеричное его нужно разбить на группы по четыре цифры и преобразовать каждую группу в шестнадцатеричную цифру.
Например:
1100111 2 = 0110 0111 2 = 67 16 ;
11,1001 2 = 0011,1001 2 = 3,9 16 ;
110,0111001 2 = 0110,0111 0010 2 = 65,72 16 .
Для перевода шестнадцатеричного числа в двоичный код необходимо каждую цифру этого числа представить четверкой двоичных цифр.
Например:
1234,AB77 16 = 0001 0010 0011 0100,1010 1011 0111 0111 2 = 1 0010 0011 0100,1010 1011 0111 0111 2 ;
CE4567 16 = 1100 1110 0100 0101 0110 0111 2 .
При переводе числа из одной произвольной системы счисления в другую нужно выполнить промежуточное преобразование в десятичное число. При переходе из восьмеричного счисления в шестнадцатеричное и обратно используется вспомогательный двоичный код числа.
Например, переведем троичное число 211 3 в семеричную систему счисления. Для этого сначала преобразуем число 211 3 в десятичное, записав его развернутую форму:
211 3 = 2 ⋅ 3 2 + 1 ⋅ 3 1 + 1 ⋅ 3 0 = 18 + 3 + 1 = 22 10 .
Затем переведем десятичное число 22 10 в семеричную систему счисления делением нацело на основание новой системы счисления, т. е. на 7:
Итак, 211 3 = 31 7 .
Примеры решения задач
Пример 1. В системе счисления с некоторым основанием число 12 записывается в виде 110. Указать это основание.
Решение. Обозначим искомое основание п. По правилу записи чисел в позиционных системах счисления 12 10 = 110 n = 0 ·n 0 + 1 · n 1 + 1 · n 2 . Составим уравнение: n 2 + n = 12 . Найдем натуральный корень уравнения (отрицательный корень не подходит, т. к. основание системы счисления, по определению, натуральное число большее единицы): n = 3 . Проверим полученный ответ: 110 3 = 0· 3 0 + 1 · 3 1 + 1 · 3 2 = 0 + 3 + 9 = 12 .
Ответ: 3.
Пример 2. Указать через запятую в порядке возрастания все основания систем счисления, в которых запись числа 22 оканчивается на 4.
Решение. Последняя цифра в записи числа представляет собой остаток от деления числа на основание системы счисления. 22 - 4 = 18. Найдем делители числа 18. Это числа 2, 3, 6, 9, 18. Числа 2 и 3 не подходят, т. к. в системах счисления с основаниями 2 и 3 нет цифры 4. Значит, искомыми основаниями являются числа 6, 9 и 18. Проверим полученный результат, записав число 22 в указанных системах счисления: 22 10 = 34 6 = 24 9 = 14 18 .
Ответ: 6, 9, 18.
Пример 3. Указать через запятую в порядке возрастания все числа, не превосходящие 25, запись которых в двоичной системе счисления оканчивается на 101. Ответ записать в десятичной системе счисления.
Решение. Для удобства воспользуемся восьмеричной системой счисления. 101 2 = 5 8 . Тогда число х можно представить как x = 5 · 8 0 + a 1 · 8 1 + a 2 · 8 2 + a 3 · 8 3 + ... , где a 1 , a 2 , a 3 , … — цифры восьмеричной системы. Искомые числа не должны превосходить 25, поэтому разложение нужно ограничить двумя первыми слагаемыми (8 2 > 25), т. е. такие числа должны иметь представление x = 5 + a 1 · 8. Поскольку x ≤ 25 , допустимыми значениями a 1 будут 0, 1, 2. Подставив эти значения в выражение для х, получим искомые числа:
a 1 = 0; x = 5 + 0 · 8 = 5;.
a 1 =1; x = 5 + 1 · 8 = 13;.
a 1 = 2; x = 5 + 2 · 8 = 21;.
Выполним проверку:
13 10 = 1101 2 ;
21 10 = 10101 2 .
Ответ: 5, 13, 21.
Арифметические операции в позиционных системах счисления
Правила выполнения арифметических действий над двоичными числами задаются таблицами сложения, вычитания и умножения.
Правило выполнения операции сложения одинаково для всех систем счисления: если сумма складываемых цифр больше или равна основанию системы счисления, то единица переносится в следующий слева разряд. При вычитании, если необходимо, делают заем.
Пример выполнения сложения : сложим двоичные числа 111 и 101, 10101 и 1111:

Пример выполнения вычитания: вычтем двоичные числа 10001 - 101 и 11011 - 1101:

Пример выполнения умножения: умножим двоичные числа 110 и 11, 111 и 101:

Аналогично выполняются арифметические действия в восьмеричной, шестнадцатеричной и других системах счисления. При этом необходимо учитывать, что величина переноса в следующий разряд при сложении и заем из старшего разряда при вычитании определяется величиной основания системы счисления.
Например, выполним сложение восьмеричных чисел 36 8 и 15 8 , а также вычитание шестнадцатеричных чисел 9С 16 и 67 16:

При выполнении арифметических операций над числами, представленными в разных системах счисления, нужно предварительно перевести их в одну и ту же систему.
Представление чисел в компьютере
Формат с фиксированной запятой
В памяти компьютера целые числа хранятся в формате с фиксированной запятой : каждому разряду ячейки памяти соответствует один и тот же разряд числа, «запятая» находится вне разрядной сетки.
Для хранения целых неотрицательных чисел отводится 8 битов памяти. Минимальное число соответствует восьми нулям, хранящимся в восьми битах ячейки памяти, и равно 0. Максимальное число соответствует восьми единицам и равно
1 ⋅ 2 7 + 1 ⋅ 2 6 + 1 ⋅ 2 5 + 1 ⋅ 2 4 + 1 ⋅ 2 3 + 1 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = 255 10 .
Таким образом, диапазон изменения целых неотрицательных чисел — от 0 до 255.
Для п-разрядного представления диапазон будет составлять от 0 до 2 n - 1.
Для хранения целых чисел со знаком отводится 2 байта памяти (16 битов). Старший разряд отводится под знак числа: если число положительное, то в знаковый разряд записывается 0, если число отрицательное — 1. Такое представление чисел в компьютере называется прямым кодом .
Для представления отрицательных чисел используется дополнительный код . Он позволяет заменить арифметическую операцию вычитания операцией сложения, что существенно упрощает работу процессора и увеличивает его быстродействие. Дополнительный код отрицательного числа А, хранящегося в п ячейках, равен 2 n − |А|.
Алгоритм получения дополнительного кода отрицательного числа:
1. Записать прямой код числа в п двоичных разрядах.
2. Получить обратный код числа . (Обратный код образуется из прямого кода заменой нулей единицами, а единиц — нулями, кроме цифр знакового разряда. Для положительных чисел обратный код совпадает с прямым. Используется как промежуточное звено для получения дополнительного кода.)
3. Прибавить единицу к полученному обратному коду.
Например, получим дополнительный код числа -2014 10 для шестнадцатиразрядного представления:
При алгебраическом сложении двоичных чисел с использованием дополнительного кода положительные слагаемые представляют в прямом коде, а отрицательные — в дополнительном коде. Затем суммируют эти коды, включая знаковые разряды, которые при этом рассматриваются как старшие разряды. При переносе из знакового разряда единицу переноса отбрасывают. В результате получают алгебраическую сумму в прямом коде, если эта сумма положительная, и в дополнительном — если сумма отрицательная.
Например:
1) Найдем разность 13 10 - 12 10 для восьмибитного представления. Представим заданные числа в двоичной системе счисления:
13 10 = 1101 2 и 12 10 = 1100 2 .
Запишем прямой, обратный и дополнительный коды для числа -12 10 и прямой код для числа 13 10 в восьми битах:
Вычитание заменим сложением (для удобства контроля за знаковым разрядом условно отделим его знаком «_»):

Так как произошел перенос из знакового разряда, первую единицу отбрасываем, и в результате получаем 00000001.
2) Найдем разность 8 10 - 13 10 для восьмибитного представления.
Запишем прямой, обратный и дополнительный коды для числа -13 10 и прямой код для числа 8 10 в восьми битах:
Вычитание заменим сложением:
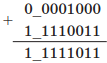
В знаковом разряде стоит единица, а значит, результат получен в дополнительном коде. Перейдем от дополнительного кода к обратному, вычтя единицу:
11111011 - 00000001 = 11111010.
Перейдем от обратного кода к прямому, инвертируя все цифры, за исключением знакового (старшего) разряда: 10000101. Это десятичное число -5 10 .
Так как при п-разрядном представлении отрицательного числа А в дополнительном коде старший разряд выделяется для хранения знака числа, минимальное отрицательное число равно: А = -2 n-1 , а максимальное: |А| = 2 n-1 или А = -2 n-1 - 1.
Определим диапазон чисел, которые могут храниться в оперативной памяти в формате длинных целых чисел со знаком (для хранения таких чисел отводится 32 бита памяти). Минимальное отрицательное число равно
А = -2 31 = -2147483648 10 .
Максимальное положительное число равно
А = 2 31 - 1 = 2147483647 10 .
Достоинствами формата с фиксированной запятой являются простота и наглядность представления чисел, простота алгоритмов реализации арифметических операций. Недостатком является небольшой диапазон представимых чисел, недостаточный для решения большинства прикладных задач.
Формат с плавающей запятой
Вещественные числа хранятся и обрабатываются в компьютере в формате с плавающей запятой , использующем экспоненциальную форму записи чисел.
Число в экспоненциальном формате представляется в таком виде:
где $m$ — мантисса числа (правильная отличная от нуля дробь);
$q$ — основание системы счисления;
$n$ — порядок числа.
Например, десятичное число 2674,381 в экспоненциальной форме запишется так:
2674,381 = 0,2674381 ⋅ 10 4 .
Число в формате с плавающей запятой может занимать в памяти 4 байта (обычная точность ) или 8 байтов (двойная точность ). При записи числа выделяются разряды для хранения знака мантиссы, знака порядка, порядка и мантиссы. Две последние величины определяют диапазон изменения чисел и их точность.
Определим диапазон (порядок) и точность (мантиссу) для формата чисел обычной точности, т. е. четырехбайтных. Из 32 битов 8 выделяется для хранения порядка и его знака и 24 — для хранения мантиссы и ее знака.
Найдем максимальное значение порядка числа. Из 8 разрядов старший разряд используется для хранения знака порядка, остальные 7 — для записи величины порядка. Значит, максимальное значение равно 1111111 2 = 127 10 . Так как числа представляются в двоичной системе счисления, то
$q^n = 2^{127}≈ 1.7 · 10^{38}$.
Аналогично, максимальное значение мантиссы равно
$m = 2^{23} - 1 ≈ 2^{23} = 2^{(10 · 2.3)} ≈ 1000^{2.3} = 10^{(3 · 2.3)} ≈ 10^7$.
Таким образом, диапазон чисел обычной точности составляет $±1.7 · 10^{38}$.
Кодирование текстовой информации. Кодировка ASCII. Основные используемые кодировки кириллицы
Соответствие между набором символов и набором числовых значений называется кодировкой символа. При вводе в компьютер текстовой информации происходит ее двоичное кодирование. Код символа хранится в оперативной памяти компьютера. В процессе вывода символа на экран производится обратная операция — декодирование , т. е. преобразование кода символа в его изображение.
Присвоенный каждому символу конкретный числовой код фиксируется в кодовых таблицах. Одному и тому же символу в разных кодовых таблицах могут соответствовать разные числовые коды. Необходимые перекодировки текста обычно выполняют специальные программы-конверторы, встроенные в большинство приложений.
Как правило, для хранения кода символа используется один байт (восемь битов), поэтому коды символов могут принимать значение от 0 до 255. Такие кодировки называют однобайтными . Они позволяют использовать 256 символов (N = 2 I = 2 8 = 256). Таблица однобайтных кодов символов называется ASCII (American Standard Code for Information Interchange — Американский стандартный код для обмена информацией). Первая часть таблицы ASCII-кодов (от 0 до 127) одинакова для всех IBM-PC совместимых компьютеров и содержит:
- коды управляющих символов;
- коды цифр, арифметических операций, знаков препинания;
- некоторые специальные символы;
- коды больших и маленьких латинских букв.
Вторая часть таблицы (коды от 128 до 255) бывает различной в различных компьютерах. Она содержит коды букв национального алфавита, коды некоторых математических символов, коды символов псевдографики. Для русских букв в настоящее время используется пять различных кодовых таблиц: КОИ-8, СР1251, СР866, Мас, ISO.
В последнее время широкое распространение получил новый международный стандарт Unicode . В нем отводится по два байта (16 битов) для кодирования каждого символа, поэтому с его помощью можно закодировать 65536 различных символов (N = 2 16 = 65536). Коды символов могут принимать значение от 0 до 65535.
Примеры решения задач
Пример. С помощью кодировки Unicode закодирована следующая фраза:
Я хочу поступить в университет!
Оценить информационный объем этой фразы.
Решение. В данной фразе содержится 31 символ (включая пробелы и знак препинания). Поскольку в кодировке Unicode каждому символу отводится 2 байта памяти, для всей фразы понадобится 31 ⋅ 2 = 62 байта или 31 ⋅ 2 ⋅ 8 = 496 битов.
Ответ: 32 байта или 496 битов.
Здравствуйте! Меня зовут Александр Георгиевич! Я работаю репетитором по , и уже на протяжении 10 лет.
Ключевые направления моей преподавательской деятельности:
Подготовка школьников к успешной сдаче и по информатике и математике.
Подготовка студентов по различным .
Выполнение на заказ всевозможных .
Ведение образовательного YouTube-канала , на который я регулярно выкладываю мультимедийные видеоматериалы.
Если у вас есть непонимания, что такое « Декодирование информации » и что под этим процессом понимается, то рекомендую вам записаться на . На своих частных занятиях я со своими учениками помимо знакомства с теоретической частью решаю колоссальное количество различных тематических примеров.
В отличие от большинства других репетиторов я предлагаю своим клиентам абсолютно любые взаимодействия:
Информация, свойства информации, кодирование информации
Прежде чем переходить к анализу сведений, связанных с декодированием информации , вам в обязательном порядке стоит освежить в памяти такие темы, как « » и « ».
С таким понятием как «Декодирование информации » неразрывно связано другое – « ». Эти процессы являются антагонистами, то есть противопоставляются друг другу. Процесс декодирования невозможен без начального процесса кодирования какой-либо информации.
Если бы не существовало кодирования информации, то тогда бы не требовалось и проводить декодирование.
Рассмотрим два конкретных примера. Первый – бытовой, второй – промышленный.
Вы хотите передать другу текстовое email-сообщение, но не в обычном русскоязычном варианте, а специальном, чтобы никто не смог его правильно прочитать. Следовательно, вы задумываетесь о том, каким образом его можно зашифровать, закодировать. Не долго думая, вы выбираете следующий способ кодирования.
В чем его суть: каждую русскую букву передаваемого сообщения вы заменяется на букву, стоящую в алфавите через 5 позиций дальше. То есть буква « а» становится буквой «е», буква «б» становится буквой «ё» и так далее. По факту вы производите сдвиг позиции буквы на 5 единиц вперед.
Да, подобное кодирование крайне неустойчивое и легко «взламывается» злоумышленниками, но большинство людей не смогу раскодировать подобное сообщение за разумное время, так как не догадаются об алгоритме шифрования.
Когда ваш друг получает от вас закодированное текстовое сообщение он должен его декодировать, то есть воспользоваться алгоритмом вашего кодирования, но в «обратную сторону». Чтобы декодировать информацию , представленную таким информационным сообщением, ему следует произвести сдвиг каждой буквы на 5 позиций назад.
То есть буква «ё» станет буквой «б», а буква «е» станет буквой «а» и так далее. Это пример простейшего, тривиального кодирования и декодирования информации .
Пример промышленного "банковского" кодирования и декодирования информации
Давайте рассмотрим более сложный вариант шифрования информации. Допустим банковский служащий планирует передать в другую страну документ, содержащий информацию о банковских счетах клиентов банка. Передавать подобное сообщение в незащищенном варианте абсолютно опасно.
Существует большое количество устойчивых алгоритмов кодирования информации, я лишь вкратце поясню суть. Сначала вычисляется контрольная сумма файла (под файлом можно понимать передаваемый документ), затем файл разбивается на несколько пакетов.
Для каждого пакета также вычисляется контрольная сумма. Информация внутри каждого пакета кодируется одним из сложнейших современных алгоритмов шифрования. После этого начинается передача пакетов адресату. Адресат, получая пакеты, отправляет отправителю контрольные суммы.
Если контрольные суммы пакетов у отправителя и адресата совпадают, то все в порядке, несанкционированного доступа к этим пакетам не проводилось. Когда все пакеты переданы, они комплектуются в единый файл, происходит этап декодирования информации .
Разная информация кодируется по-разному
Также вам нужно понимать, что разные виды информации проходят различную обработку при декодировании. Под разными видами информации следует понимать
Остались вопросы? Звоните и записывайтесь на первый урок!
Если у вас остались вопросы, касающиеся декодирования информации , то звоните мне на мобильный телефон и записывайтесь на индивидуальные уроки по информатике и ИКТ. Я смогу вам пояснить абсолютно любой момент из данной темы, а также продемонстрирую на примерах, как правильно проводить декодирование «сложной» информации.
Своим потенциальным клиентам я предлагаю финансового взаимодействия, поэтому даже самый взыскательные клиент сумеет подобрать вариант, полностью удовлетворяющий его текущим потребностям.
КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ
Процесс представления информации в определенной стандартной форме и обратный процесс восстановления информации по ее такому представлению. В математич. литературе кодированием наз. произвольного множества Ав конечных последовательностей (слов) в нек-ром алфавите В, а декодированием - . Примерами кодирования являются: представление натуральных чисел в r-ичной системе счисления, при к-ром каждому числу N=i, 2, ... ставится в слово b 1 b 2 ... b l в алфавите В r = {0, 1, ..., r-1} такое, что b 1 неравно 0 и b 1 r l -1 +...+ b l -1 r+b l =N; текстов на русском языке с помощью телеграфного кода в последовательности, составленные из посылок тока и пауз различной длительности; отображение, применяемое при написании цифр почтового индекса (см. рис.). В последнем случае каждой десятичной цифре соответствует слово в алфавите В 2 = {0, 1} длины 9, в котором символами 1 отмечены номера использованных линий (напр., цифре 5 соответствует слово 110010011). Исследование различных свойств К. и д. и построение эффективных в определенном смысле кодирований, обладающих требуемыми свойствами, составляет проблематику теории кодирования. Обычно критерий эффективности кодирования так или иначе связан с минимизацией длин кодовых слов (образов
элементов множества А), а требуемые свойства кодирования связаны с обеспечением заданного уровня помехоустойчивости, понимаемой в том или ином смысле. В частности, под помехоустойчивостью понимается возможность однозначного декодирования при отсутствии или допустимом уровне искажений в кодовых словах. Помимо помехоустойчивости, к кодированию может предъявляться дополнительных требований. Напр., при выборе кодирования для цифр почтового индекса необходимо согласование с обычным способом написания цифр. В качестве дополнительных требований часто используются ограничения, связанные с допустимой сложностью схем, осуществляющих К. и д. Проблематика теории кодирования в основном создавалась под влиянием разработанной К. Шенноном (С. Shannon, ) теории передачи информации. Источником новых задач теории кодирования служат создание и совершенствование автоматизированных систем сбора, хранения, передачи и обработки информации. Методы решения задач теории кодирования главным образом комбинаторные, теоретико-вероятностные и алгебраические. Произвольное кодирование f множества (алфавита) Асловами в алфавите Вможно распространить на множество А* всех слов в А(сообщений) следующим образом:
где i=1, 2, . . ., k. Такое отображение f: наз. побуквенным кодированием сооб. щений. Более общий кодирований сообщений образуют автоматные кодирования, реализуемые инициальными асинхронными автоматами, выдающими в каждый времени нек-рое (быть может, пустое) слово в алфавите В. Содержательный смысл этого обобщения заключается в том, что в разных состояниях реализует различные кодирования букв алфавита сообщений. Побуквенное кодирование - это автоматное кодирование, реализуемое автоматом с одним состоянием: Одним из направлений теории кодирования является изучение общих свойств кодирования и построение алгоритмов распознавания этих свойств (см. Кодирование алфавитное ). В частности, для побуквенных и автоматных кодирований найдены необходимые и достаточные условия для того, чтобы:
1) было однозначным, 2) существовал декодирующий автомат, т. е. автомат, реализующий декодирование с нек-рой ограниченной задержкой, 3) существовал самонастраивающийся декодирующий автомат (позволяющий в течение ограниченного промежутка времени устранить влияние сбоя во входной последовательности или в работе самого автомата).
Большинство задач теории кодирования сводится к изучению конечных или счетных множеств слов в алфавите В r .
Такие множества наз. кодами. В частности, каждому однозначному кодированию f: (и побуквенному кодированию ![]() ) соответствует Одно из основных утверждений теории кодирования состоит в том, что условие взаимной однозначности побуквенного кодирования
) соответствует Одно из основных утверждений теории кодирования состоит в том, что условие взаимной однозначности побуквенного кодирования ![]() накладывает следующее ограничение на длины li=l,if
)кодовых слов f(i):
накладывает следующее ограничение на длины li=l,if
)кодовых слов f(i):
Справедливо и обратное утверждение: если (l 0 , ..
., l m
-1)- набор натуральных чисел, удовлетворяющих (1), то существует взаимно однозначное побуквенное кодирование ![]() такое, что слово f(i)имеет длину l i
;.
При этом, если числа l i
упорядочены по возрастанию, то в качестве f(i) можно взять первые после запятой l i
символов разложения числа в r-ичную (метод Шеннона).
такое, что слово f(i)имеет длину l i
;.
При этом, если числа l i
упорядочены по возрастанию, то в качестве f(i) можно взять первые после запятой l i
символов разложения числа в r-ичную (метод Шеннона).
Наиболее законченные результаты в теории кодирования связаны с построением эффективных взаимно однозначных кодирований. Описанные здесь конструкции используются на практике для сжатия информации и выборки информации из памяти. Понятие эффективности кодирования зависит от выбора критерия стоимости. При определении стоимости L(f)взаимно однозначного побуквенного кодирования ![]() предполагается, что каждому числу поставлено в соответствие положительное р i
и Р=
{р 0 , ..., P m-1
).
Исследованы следующие варианты определения стоимости L(f):
предполагается, что каждому числу поставлено в соответствие положительное р i
и Р=
{р 0 , ..., P m-1
).
Исследованы следующие варианты определения стоимости L(f):

причем предполагается, что в первых двух случаях р i
- вероятности, с к-рыми некоторый бернуллиевый порождает соответствующие буквы алфавита В т
![]() а в третьем случае р i
- заданные длины кодовых слов. При первом определении стоимость равна средней длине кодового слова, при втором определении с ростом параметра tболее длинные кодовые слова оказывают все большее влияние на стоимость (
а в третьем случае р i
- заданные длины кодовых слов. При первом определении стоимость равна средней длине кодового слова, при втором определении с ростом параметра tболее длинные кодовые слова оказывают все большее влияние на стоимость (![]() при и
при и ![]() при ), при. третьем определении стоимость равна максимальному превышению длины l i
кодового слова над заданной длиной р i
. Задача построения взаимно однозначного побуквенного кодирования f: В* т ->В* r ,
минимизирующего стоимость L(f),
равносильна задаче минимизации функции L(f) на наборах (l 0 , ..., 1 т-1
)из натуральных чисел, удовлетворяющих (1). Решение этой задачи известно при каждом из указанных определений стоимости. Пусть величины L(f)на наборах (l 0 ,
. . ., l m-1
)из произвольных (не обязательно натуральных) чисел равен L r
(P)и достигается на наборе (l 0
(Р), ...,
l т-1
(Р)).
Неотрицательная I(f) = L
(f) - L r
(P)наз. избыточностью, а величина I(f)/L
(f)- относительной избыточностью кодирования f. Для избыточности взаимно однозначного кодирования
при ), при. третьем определении стоимость равна максимальному превышению длины l i
кодового слова над заданной длиной р i
. Задача построения взаимно однозначного побуквенного кодирования f: В* т ->В* r ,
минимизирующего стоимость L(f),
равносильна задаче минимизации функции L(f) на наборах (l 0 , ..., 1 т-1
)из натуральных чисел, удовлетворяющих (1). Решение этой задачи известно при каждом из указанных определений стоимости. Пусть величины L(f)на наборах (l 0 ,
. . ., l m-1
)из произвольных (не обязательно натуральных) чисел равен L r
(P)и достигается на наборе (l 0
(Р), ...,
l т-1
(Р)).
Неотрицательная I(f) = L
(f) - L r
(P)наз. избыточностью, а величина I(f)/L
(f)- относительной избыточностью кодирования f. Для избыточности взаимно однозначного кодирования ![]() построенного по методу Шеннона для длин справедливо I(f)<1. При первом, наиболее употребительном, определении стоимости как среднего числа кодовых символов, приходящихся на одну букву порождаемого источником сообщения, величина L r
(P)равна энтропии Шеннона
построенного по методу Шеннона для длин справедливо I(f)<1. При первом, наиболее употребительном, определении стоимости как среднего числа кодовых символов, приходящихся на одну букву порождаемого источником сообщения, величина L r
(P)равна энтропии Шеннона

источника, вычисленной по основанию r,
a l i
(P)=-log r p i .
Граница избыточности I(f) = L ср (f)- Н r
(P)<
1 может быть улучшена с помощью так наз. кодирования блоками длины k,
при к-ром сообщения длины k(а не отдельные буквы) кодируются по методу Шеннона. Избыточность такого кодирования не превышает 1/k.
Этот же прием используется для эффективного кодирования зависимых источников. В связи с тем, что определение длин l i
при кодировании по методу Шеннона основано на знании статистики источника, для нек-рых классов источников разработаны методы построения универсального кодирования, гарантирующего определенную верхнюю границу избыточности для любого источника из этого класса. В частности, построено кодирование блоками длины к,
избыточность к-рого для любого бернуллиевого источника асимптотически не превышает ![]() (при фиксированных ), причем эта асимптотическая не может быть улучшена.
(при фиксированных ), причем эта асимптотическая не может быть улучшена.
продолжение Кодирование и декодорование...
Наряду с задачами эффективного сжатия информации рассмотрены задачи оценки избыточности конкретных видов сообщений. Напр., была оценена относительная избыточность нек-рых естественных языков (в частности, английского и русского) в предположении, что тексты на них порождаются марковскими источниками с большим числом состояний.
При исследовании задач построения эффективных помехоустойчивых кодирований обычно рассматривают кодирования ![]() к-рым соответствуют коды {f(0), . .., f(m-1)}, принадлежащие множеству слов длины пв алфавите В r ,
и предполагают, чтo буквы алфавита сообщений В т
равновероятны. Эффективность такого кодирования оценивают избыточностью I(f)= п-log r m
или скоростью передачи В(f)= При определении помехоустойчивости кодирования формализуется понятие ошибки и вводится в рассмотрение нек-рая образования ошибок. Ошибкой типа замещения (или просто ошибкой) наз. преобразование слова, состоящее в замещении одного из его символов другим символом алфавита В r .
Напр., проведение лишней линии при написании почтового индекса приводит к замещению в кодовом слове символа 0 символом 1, а отсутствие нужной линии - к замещению символа 1 символом 0. Возможность обнаружения и исправления ошибок основана на том, что для кодирования f, обладающего ненулевой избыточностью, декодирование f -1 может быть произвольным образом доопределено на r п
-тсловах из не являющихся кодовыми. В частности, если множество разбито на тнепересекающихся подмножеств D 0 , . .
., D m-1 таких, что а декодирование f -1
доопределено так, что f -1
(D i
)=i,
то при декодировании будут исправлены все ошибки, преобразующие кодовое слово f(i) в D i
, i=0, ..., т-1. Аналогичная возможность имеется и в случае ошибок других типов таких, как стирание символа (замещение символом другого алфавита), изменение числового значения кодового слова на b=1, ..., r-1, i=0, 1, ... (арифметическая ошибка), выпадение или вставка символа и т. п.
к-рым соответствуют коды {f(0), . .., f(m-1)}, принадлежащие множеству слов длины пв алфавите В r ,
и предполагают, чтo буквы алфавита сообщений В т
равновероятны. Эффективность такого кодирования оценивают избыточностью I(f)= п-log r m
или скоростью передачи В(f)= При определении помехоустойчивости кодирования формализуется понятие ошибки и вводится в рассмотрение нек-рая образования ошибок. Ошибкой типа замещения (или просто ошибкой) наз. преобразование слова, состоящее в замещении одного из его символов другим символом алфавита В r .
Напр., проведение лишней линии при написании почтового индекса приводит к замещению в кодовом слове символа 0 символом 1, а отсутствие нужной линии - к замещению символа 1 символом 0. Возможность обнаружения и исправления ошибок основана на том, что для кодирования f, обладающего ненулевой избыточностью, декодирование f -1 может быть произвольным образом доопределено на r п
-тсловах из не являющихся кодовыми. В частности, если множество разбито на тнепересекающихся подмножеств D 0 , . .
., D m-1 таких, что а декодирование f -1
доопределено так, что f -1
(D i
)=i,
то при декодировании будут исправлены все ошибки, преобразующие кодовое слово f(i) в D i
, i=0, ..., т-1. Аналогичная возможность имеется и в случае ошибок других типов таких, как стирание символа (замещение символом другого алфавита), изменение числового значения кодового слова на b=1, ..., r-1, i=0, 1, ... (арифметическая ошибка), выпадение или вставка символа и т. п.
В теории передачи информации (см. Информации передача )рассматриваются вероятностные модели образования ошибок, называемые каналами. Простейший задается вероятностями р ij замещения символа iсимволом j. Для канала определяется величина (пропускная способность)
где максимум берется по всем наборам (q 0 , . . ., q m-1
)таким, что
и ![]() Эффективность кодирования f характеризуется скоростью передачи R(f),
а помехоустойчивость - средней вероятностью ошибки декодирования Р(f) (при наилучшем разбиении. В n r
на подмножества D i
). Основной результат теории передачи информации ( Шеннона) состоит в том, что пропускная способность Сявляется верхней гранью чисел Rтаких, что для любого е>0 при всех п,
начиная с нек-рого, существует кодирование
Эффективность кодирования f характеризуется скоростью передачи R(f),
а помехоустойчивость - средней вероятностью ошибки декодирования Р(f) (при наилучшем разбиении. В n r
на подмножества D i
). Основной результат теории передачи информации ( Шеннона) состоит в том, что пропускная способность Сявляется верхней гранью чисел Rтаких, что для любого е>0 при всех п,
начиная с нек-рого, существует кодирование
Другая модель образования ошибок (см. Код с исправлением ошибок, Код с исправлением арифметических ошибок, Код с исправлением выпадений и вставок
)характеризуется тем, что в каждом слове длины ппроисходит не более заданного числа tошибок. Пусть E i
(t)- множество слов, получаемых из f(i)в результате tили менее ошибок. Если для кода множества E i
(t), i=0, ..., m-1, попарно не пересекаются, то при декодировании таком, что E i
(t)Н D i
, будут исправлены все ошибки, допустимые рассматриваемой моделью образования ошибок, и такой код наз. кодом с исправлением tошибок. Для многих типов ошибок (напр., замещений, арифметич. ошибок, выпадений и вставок) d( х, у
),
равная минимальному числу ошибок данного типа, преобразующих слово в слово является метрикой, а множества E i
(t)- метрическими шарами радиуса t.
Поэтому задача построения наиболее эффективного (т. е. максимального по числу слов т)кода в В n r
с исправлением tошибок равносильна задаче плотнейшей упаковки метрического пространства шарами радиуса t.
Код для цифр почтового индекса не является кодом с исправлением одной ошибки, так как d(f(0), f
(8))=1 и d(f(5), f
(8)) = 2, хотя все другие расстояния между кодовыми словами не менее 3. Задача исследования величины I r
(n, t
)- минимальной избыточности кода в с исправлением tошибок типа замещения распадается на два основных случая. В первом случае, когда tфиксировано, а справедлива асимптотика причем достигается "мощностная" граница, основанная на подсчете числа слов длины пв шаре радиуса t.
Асимптотика величины I r
(n, t
)при г>2, а также при r=2 для многих других типов ошибок (напр., арифметич. ошибок, выпадений и вставок) не известна (1978). Во втором случае, когда t=
[pn
],
где р - некоторое фиксированное число, 0<р<(r-1)/2r, а "мощностная" граница где T r
(p)=-p log r
(p/
(r-
1))-(1-р)log r (l- p),
существенно улучшена. Имеется предположение, что верхняя граница полученная методом случайного выбора кода, является асимптотически точной, т. е. I r
( п,
[ рп
])~пТ r
(2р
).
Доказательство или опровержение этого предположения - одна из центральных задач теории кодирования. Большинство конструкций помехоустойчивых кодов являются эффективными, когда пкода достаточно велика. В связи с этим особое значение приобретают вопросы, связанные со сложностью устройств, осуществляющих кодирование и декодирование (кодера и декодера). Ограничения на допустимый тип декодера или его сложность могут приводить к увеличению избыточности, необходимой для обеспечения заданной помехоустойчивости. Напр., минимальная избыточность кода в В n 2 , для к-рого существует декодер, состоящий из регистра сдвига и одного мажоритарного элемента и исправляющий одну ошибку, имеет (ср. с (2)). В качестве математич. модели кодера и декодера обычно рассматривают схемы из функциональных элементов и под сложностью понимают число элементов в схеме. Для известных классов кодов с исправлением ошибок проведено исследование возможных алгоритмов К. и д. и получены верхние границы сложности кодера и декодера. Найдены также нек-рые соотношения между скоростью передачи кодирования, помехоустойчивостью кодирования и сложностью декодера (см. ). Еще одно исследований в теории кодирования связано с тем, что многие результаты (напр., теорема Шеннона и граница (3)) не являются "конструктивными", а представляют собой теоремы существования бесконечных последовательностей {К п }
кодов В связи с этим предпринимаются усилия, чтобы доказать эти результаты в классе таких последовательностей {К п }
кодов, для к-рых существует Тьюринга, распознающая принадлежность произвольного слова длины lмножеству за время, имеющее медленный роста относительно l(напр., llog l).
Нек-рые новые конструкции и методы получения границ, разработанные в теории кодирования, привели к существенному продвижению в вопросах, на первый взгляд весьма далеких от традиционных задач теории кодирования. Здесь следует указать на использование максимального кода с исправлением одной ошибки в асимптотически оптимальном методе реализации функций алгебры логики контактными схемами
;на принципиальное улучшение верхней границы для плотности упаковки re-мерного евклидова пространства равными шарами; на использование неравенства (1) при оценке сложности реализации формулами одного класса функций алгебры логики. Идеи и результаты теории кодирования находят свое дальнейшее развитие в задачах синтеза самокорректирующихся схем и надежных схем из ненадежных элементов. Лит.
: Шеннон К., Работы по теории информации и кибернетике, пер. с англ., М., 1963; Берлекэмп Э., Алгебраическая кодирования, пер. с англ., М., 1971; Питерсон У., Уэлдон Э., Коды, исправляющие ошибки, пер. с англ., 2 изд., М., 1976; Дискретная и математические вопросы кибернетики, т.1, М., 1974, раздел 5; Бассалыго Л. А., Зяблов В. В., Пинскер М. С, "Пробл. передачи информации", 1977, т. 13, № 3, с. 5-17; [В] Сидельников В. М., "Матем. сб.", 1974, т. 95, в. 1, с. 148 - 58. В. И. Левенштейн.
Математическая энциклопедия. - М.: Советская энциклопедия
.
И. М. Виноградов
.
1977-1985
.
См. Кодирование и декодирование … Математическая энциклопедия
- (от франц. code – свод законов, правил) – отображение (преобразование) нек рых объектов (событий, состояний) в систему конструктивных объектов (называемых кодовыми образами), совершаемое по определ. правилам, совокупность к рых наз. шифром К.,… … Философская энциклопедия
Кодирование
- Encoding Отождествление квантованного сигнала электросвязи с кодовыми словами Примечания: 1. Под кодовым словом понимается упорядоченная последовательность символов некоторого алфавита. 2. В конкретных устройствах квантование сигнала электросвязи … Словарь-справочник терминов нормативно-технической документации
Установление соответствия между элементами сообщения и сигналами, при помощи к рых эти элементы могут быть зафиксированы. Пусть В, множество элементов сообщения, А алфавит с символами, Пусть конечная последовательность символов наз. словом в… … Физическая энциклопедия
Декодировка, дешифрование, дешифровка, дешифрирование, расшифровка, расшифровывание. Ant. кодирование Словарь русских синонимов. декодирование сущ., кол во синонимов: 8 декодировка (8) … Словарь синонимов
декодирование
- Восстановление дискретного сообщения по сигналу на выходе дискретного канала, осуществляемое с учетом правила кодирования. [Сборник рекомендуемых терминов. Выпуск 94. Теория передачи информации. Академия наук СССР. Комитет технической… … Справочник технического переводчика
Использование электронно-вычислительной техники, предназначенной для обработки данных, является достаточно важным этапом в ходе совершенствования систем управления и планирования. Однако этот способ сбора и обработки информации имеет некоторые отличия от привычного. Что представляет собой кодирование информации?
Кодирование данных является обязательным этапом в ходе сбора и обработки данных. Обычно под кодом понимают комбинацию знаков, соответствующую передаваемой информации или некоторым их качественным характеристикам. Кодирование является процессом составления зашифрованной комбинации в форме списка сокращений или специальных символов, полностью передающих изначальный смысл послания. В некоторых случаях кодирование представляет собой шифрование, однако необходимо понимать, что последняя процедура предусматривает защиту информации от возможного взлома, а также прочтения третьими лицами. Целью кодирования является представление данных в удобном и лаконичном формате, что предполагает упрощение их передачи и обработки на вычислительной технике. Компьютеры способны оперировать только информацией конкретной формы. Таким образом, необходимо принимать это во внимание, чтобы избежать проблем. Принципиальная схема обработки информации состоит из поиска, сортировки и упорядочивании. Что касается кодирования, в ней оно встречается в процессе ввода данных в виде кода. Что представляет собой декодирование информации?
У пользователей персональных компьютеров могут возникнуть вопросы на счет того, что означает кодирование и декодирование. Причины этого могут быть самые различные, однако в любом случае необходимо ознакомить юзера с такой информацией, которая способна помочь с успехом продвигаться дальше в потоке информационных технологий. Как можно понять, после обработки данных образуется выходной код. В случае расшифровки фрагмента получается исходная информация. Другими словами, декодирование представляет собой процесс, который является обратным шифрованию. В процессе кодирования информация приобретает вид символьных сигналов, полностью соответствующих передаваемому объекту, а при декодировании из кода извлекается передаваемые данные или некоторые их характеристики. Пользователей, которые получают закодированные сообщения, может быть несколько, однако важным является то, чтобы сведения попали именно к адресату и не были раскрыты третьими лицами. Таким образом, стоит ознакомиться с процессом кодирования и декодирования данных. Они позволяют обмениваться конфиденциальной информацией между группой собеседников. Кодирование и декодирование текстовых данных
Если нажать на клавишу клавиатуры, компьютер получает сигнал, представленный двоичным числом, расшифровку которого легко отыскать в кодовой таблице. Мировым стандартом считается таблица ASCII. Правда, знать, что такое кодирование и декодирование, мало. Необходимо также понимать, как размещаются данные в компьютере. Например, для хранения одного символа двоичного кода выделен 1 байт или 8 бит. Данная ячейка способна принимать лишь два значения: 0 и 1. Таким образом, выходит, что один байт дает возможность зашифровать 256 различных символов, поскольку это число комбинаций существует возможность составить. Данные сочетания и выступают в качестве ключевой части таблицы ASCII. Например, буква S кодируется в виде 01010011. Если совершить ее нажатие на клавиатуре, выполняется кодирование и декодирование данных, а пользователь получает требуемый результат, который отображается на экране. Половина таблицы стандартов ASCII имеет коды цифр, управляющих символов, а также латинских букв. Остальная ее часть заполняется следующим: Национальными знаками; Таким образом, становится понятным, что в разных странах данная часть таблицы будет различной. Цифры при вводе преобразовываются в двоичную систему вычисления в соответствии со стандартной сводкой. Компьютеры активно применяют двоичную систему счисления, где наблюдается только две цифры − 0 и 1. Изучение действий с полученными числами двоичной системы принадлежит двоичной арифметике. Многие законы основных математических действий для подобных цифр остаются актуальными. Примеры кодирования и декодирования чисел
Стоит ознакомиться с двумя способами кодировки числа 45. Когда данная цифра встречается в текстовом фрагменте, каждая ее составляющая закодирована в соответствии с таблицей стандартов ASCII, 8 битами. Таким образом, четверка обратится в 01000011, а пятерка превратится в 01010011. Когда число 45 задействовано для вычислений, используется специальная методика преобразования в восьмиразрядный двоичный код 001011012. Для его хранения требуется всего 1 байт. При увеличения монохромного изображения при помощи лупы можно увидеть, что оно включает в себя множество мелких точек, которые формируют полноценный узор. Персональные свойства каждой картинки, а также линейных координатах любой точки существует возможность отобразить в числовой форме. В этом состоит причина того, что растровое кодирование основано на двоичном коде, который приспособлен для отображения графических данных. Черно-белые изображения представлены в виде комбинации точек, имеющей различные оттенки серого цвета. Другими словами, яркость любой точки картинки определяется восьмиразрядными двоичными числами. Разложение произвольного градиента на базовые составляющие является основой кодирования графической информации. Декодирование изображений осуществляется аналогичным способом, однако в обратном направлении. При разложении задействовано три основных цвета: Зеленый; Все дело в том, что существует возможность получить любой естественный оттенок путем комбинации данных градиентов. Эта система кодирования называется RGB. Если использовать двадцать четыре двоичных разрядов, чтобы зашифровать графическое изображение, режим преобразования имеет название полноцветного. Основные цвета сравниваются с оттенками, дополняющими базовую точку, преобразовывая ее в белый цвет. Дополнительным цветом является градиент, который образован суммой других основных тонов. При этом стоит отметить желтый, пурпурный, а также голубой дополнительные цвета. Такой способ кодирования точек картинок используется и в полиграфической отрасли. Правда, в данном случае необходимо использовать четвертый цвет, который является черным. В этом и состоит причина того, что полиграфическая система преобразования обозначается аббревиатурой CMYK. Данная система для представления картинок применяет целых тридцать два двоичных разряда. Методы кодирования, а также декодирования данных предусматривают использование разных технологий. Это зависит от типа вводимой информации. Допустим, способ шифрования графических изображений при помощи шестнадцатиразрядных двоичных кодов носит название High Color. Такая технология позволяет передавать двести пятьдесят шесть оттенков. При уменьшении числа используемых двоичных разрядов, которые применяются для шифрования точек графического изображения, автоматически уменьшается объем, требуемый для временного хранения данных. Представленный вариант кодирования информации называется индексным. Кодирование звуковой информации
После того как стало понятно, что собой представляет кодирование и декодирование, а также то, какие способы лежат в основе данного процесса, необходимо подробнее рассмотреть кодирование звуковых данных. Такую информацию можно отобразить в виде элементарных единиц, а также пауз между каждой их парой. Таким образом, сигнал преобразовывается и хранится в этом виде в памяти компьютера. Звуки выводятся при помощи синтезатора речи, используемого зашифрованные комбинации, которые хранятся в памяти персонального компьютера. Человеческую речь намного тяжелее закодировать, поскольку она имеет отличия в многообразии оттенков, поэтому компьютеру нужно сравнивать каждое словосочетание со стандартом, занесенным в его память. Чтобы распознавание прошло успешно, сказанное слово должно присутствовать в словаре. Стоит отметить, что имеются разные способы реализации кодирования числовой, текстовой, а также графической информации. Как правило, декодирование данных осуществляется по обратной технологии. При выполнении кодирования чисел принимается во внимание цель, с которой цифра введена в систему. Она может состоять в арифметических вычислениях или простом выводе. Информация, кодируемая в двоичной системе, зашифровывается при помощи единиц и ноликов. Данные знаки называются битами. Такой вариант кодировки считается самым известным, поскольку его легче организовать с точки зрения технологии. Итак, присутствие сигнала обозначается единицей, отсутствие − нулем. Двоичное шифрования имеет только один недостаток, который состоит в длине комбинаций из символов. Однако в технологическом плане легче орудовать множеством простых, однотипных компонентов, чем небольшим количеством сложных. Плюсы двоичного кодирования
Эта форма является подходящей для различных видов информации. В процессе передачи данных ошибок не возникает. Персональному компьютеру существенно легче обрабатывать данные, которые закодированы при использовании данного варианта. Необходимы устройства с двумя состояниями. Минусы двоичного кодирования
Коды имеют большую длину, что способствует замедлению их обработки. К недостаткам двоичного кодирования также стоит отнести сложность восприятия таких комбинаций пользователю, не имеющему специального образования или подготовки. Сегодняшняя статья помогает узнать, что представляет собой кодирование и декодирование, а также предоставлена информация, для чего их используют. Предложенные способы преобразования данных целиком зависят от вида информации. В качестве нее может выступать не только текст, а также числа, картинки и звук. Кодирование разной информации дает возможность унифицировать форму ее представления. В электронно-вычислительных устройствах зачастую применяются принципы стандартного двоичного кодирования, преобразовывающие исходную форму представления данных в более удобный формат для хранения и обработки.![]() для к-рого и Р(f)
для к-рого и Р(f)![]()
Смотреть что такое "КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ" в других словарях:
Таким образом, необходимо совершить преобразования в систему символов, которые распознаются компьютером.
псевдографическими знаками и символами, не имеющими отношения к математике.
Кодирование чисел
Кодирование графической информации
красный;
синий.
Почему именно эти цвета?
Кодирование данных в двоичном коде